

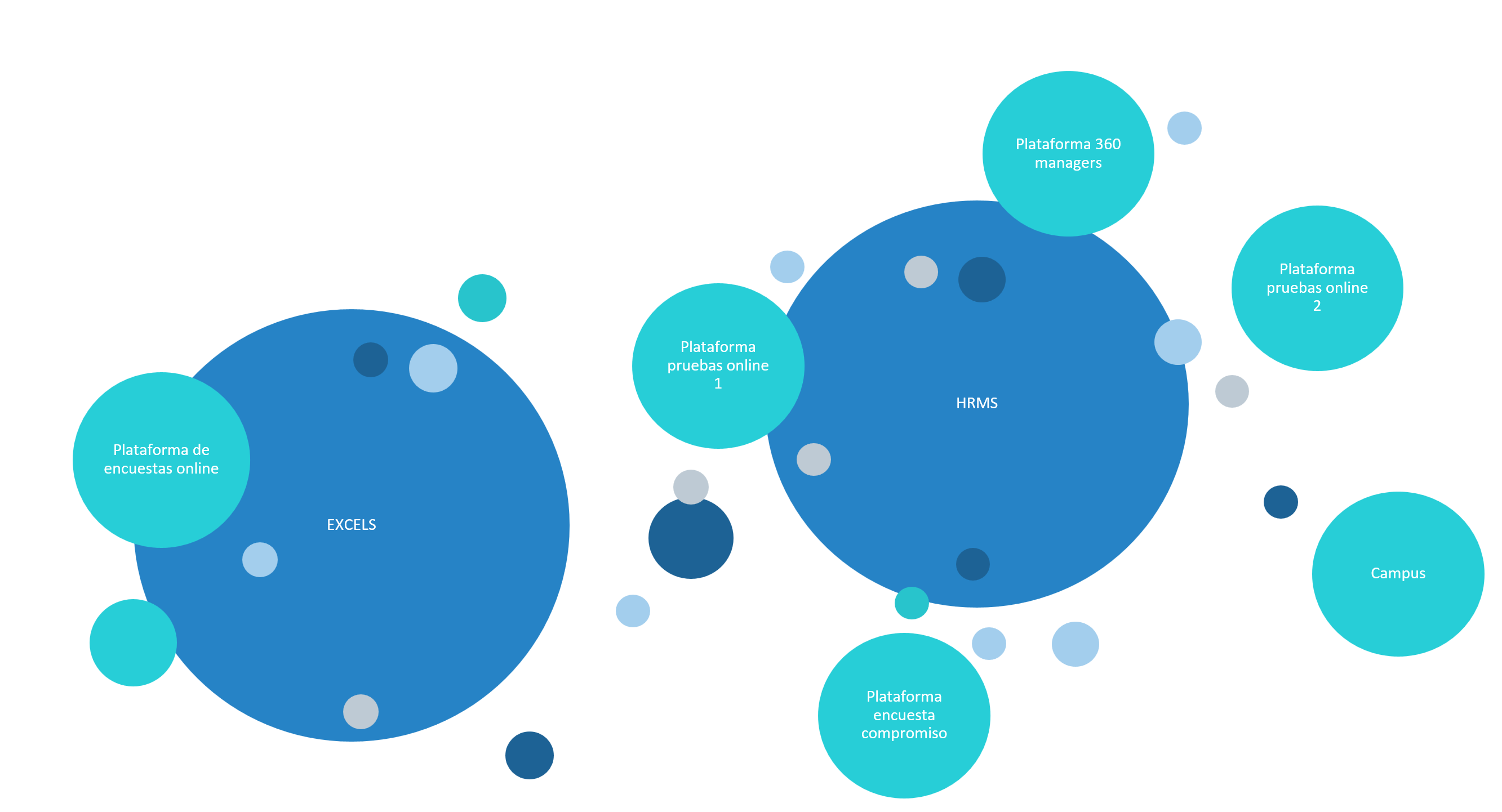
Cuando imparto clases o doy conferencias sobre introducción al mundillo de People Analytics, suelo preguntar lo mismo: ¿Dónde tenéis los datos? Al instante, numerosos alumnos comienzan a mencionar maravillosos HRMS con nombres más o menos conocidos por todos. Yo sonrío. Asiento. Y les pregunto: ¿seguro? Algunos empiezan a levantar la mano, comentando, con cierto sonrojo (porque su empresa se ha gastado una pasta en este HRMS y no quiere levantar la liebre de que no esté todo ahí como les prometieron…), que en sus empresas tienen algunas otras fuentes de información, como el otro software que usan para la nómina o el campus de formación. ¿Solo esos? Sigo sonriendo y provocándoles.
Comenzamos a levantar otras fuentes de datos: la plataforma X con la que hacemos la encuesta de clima, la plataforma Y con la que se realizan las pruebas online a candidatos… ¿Os suena? ¿Os falta algo? Yo sigo insistiendo.
Y por fin, ¡por fin!, un valiente en la clase o en el auditorio nombra al innombrable: “Yo tengo datos de compensación en un Excel”. Lo dice con aún más vergüenza. “Escuchamos, no juzgamos”, le respondo. La mayoría de las personas en la sala le miran con complicidad. “Nosotros también tenemos un fichero donde vamos cargando el estado de los candidatos”. “Nosotros tenemos en excel el listado de las personas marcadas como clave”. “Yo estoy en una PYME, y, de hecho, gestionamos la mayoría de las cosas con Excel…”.
Sonrío satisfecha. Comenzamos a entender el primer problema al que nos enfrentamos en RR.HH.: trabajamos con datos fragmentados.
Los datos fragmentados se dan cuando la información está dividida en diferentes sistemas, lo que puede dificultar su integración y análisis.
Fuente: Ana Valera.
Pero aún hay más. Yo sigo insistiendo. ¿No tenéis más datos por ahí escondidos? A alguien se le enciende la bombilla: “Los CVs en pdf o Word, los tenemos en carpetas en el drive”. ¡Bingo! Aquí podemos ver otra de las características de los datos de RR.HH.: trabajamos con datos heterogéneos.
Se habla de datos heterogéneos cuando provienen de distintas fuentes con diferentes formatos (estructurados, semiestructurados y no estructurados).
Sigamos con el ejemplo del CV en PDF. Este tipo de información es un dato no estructurado. ¿Por qué?
- Porque tienen un formato de texto libre: Los CV pueden variar enormemente en su formato, diseño y contenido. (Los candidatos son cada vez más creativos, y con la IA generativa aún más)
- Porque presentan dificultad de extracción: Aunque algunos datos (como nombre, experiencia o formación) pueden estar presentes, extraerlos
- Porque les falta una estructura fija: No hay una estructura estándar como en un archivo CSV o una base de datos relacional.
¿Cómo convertir un dato no estructurado en estructurado?
- Utilizando técnicas de procesamiento avanzado mediante IA como el NLP (Procesamiento del Lenguaje Natural), el OCR (Reconocimiento Óptico de Caracteres), etc. podemos llegar a convertir la información en dato estructurado, si bien tendremos que asumir que no todos los candidatos reflejaron la misma información, ni de lejos. Por poner ejemplos simples: algunos quizá no han indicado su dirección y otros sí, algunos quizá indican el inglés con escala del MCRE y otros con el típico “intermedio alto” o “fluido”.
- Recurriendo a un sistema de ATS (Applicant Tracking System) o un formulario en el portal de empleo de la empresa olvidaremos el CV y trabajaremos con campos bien definidos. El resultado procesado sí puede considerarse estructurado y se obtendrá la misma información de todos los candidatos.
Yo sigo impartiendo mi clase o mi charla y lanzo la siguiente pregunta: ¿Y qué pasaría si queremos cruzar los datos de desempeño de un equipo de comerciales con datos de satisfacción de clientes a los que ese equipo da servicio? Las caras son un poema entre el auditorio. “En mi caso podemos, porque todo está integrado en un data lake y podemos traérnoslo”, dice un alumno aventajado. Yo le miro y le digo: “Pues si lo tenéis en un data lake y no sois data scientist… lo tenéis crudo”. Aquí tenemos tres conceptos que están en nuestro día a día y que convendría aclarar: data lake, data warehouse y data mart.
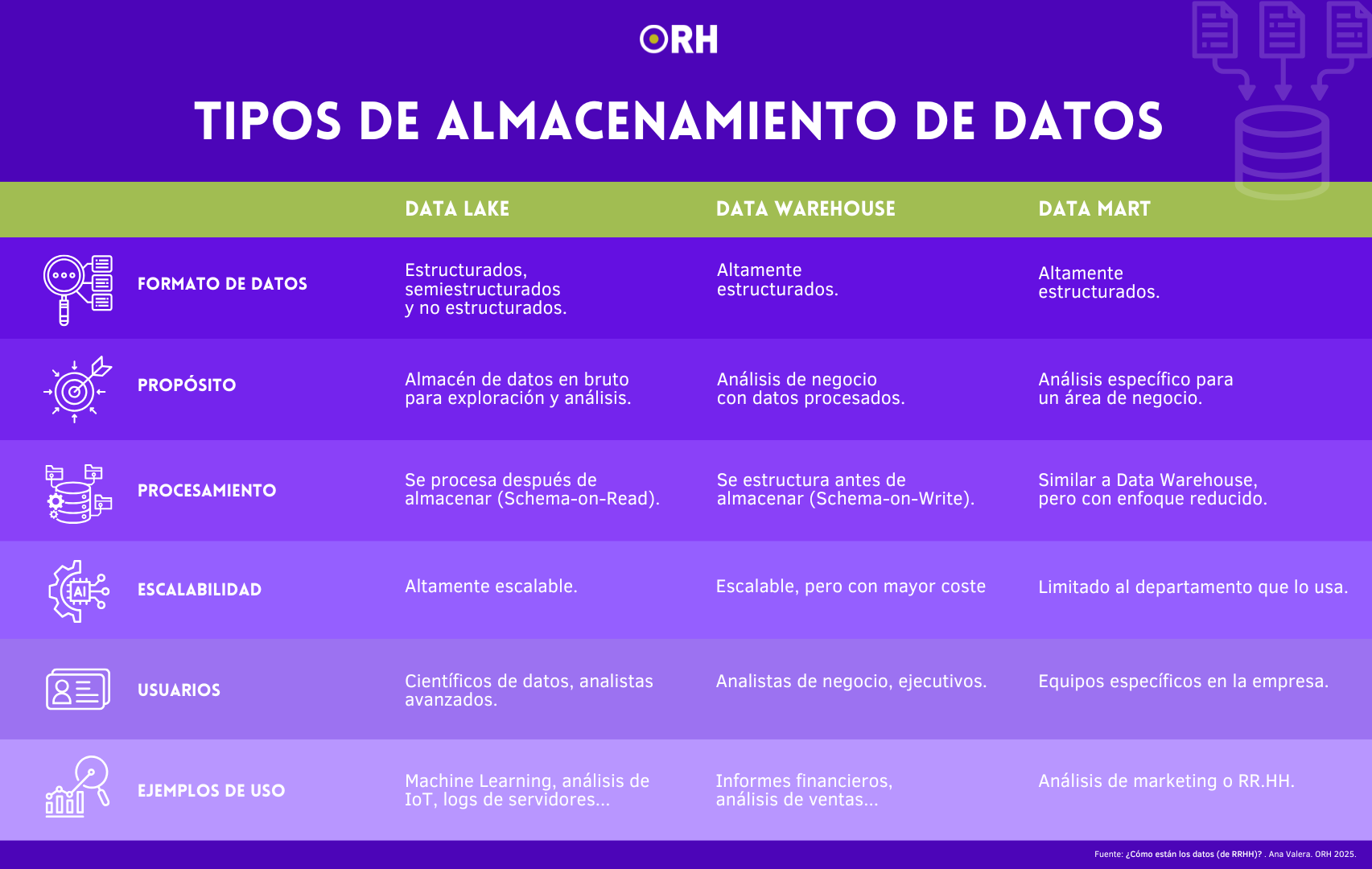
Sigamos con la pregunta sobre desempeño y satisfacción de clientes. Otro de los asistentes comenta: “Yo lo intenté, pero me dijeron en marketing que son datos suyos y que los tienen en su data mart, al que no tenemos acceso desde RR.HH.”. Ahí esta otra de las características con las que nos solemos encontrar, y es que trabajamos en silos de datos.
Los silos de datos hacen referencia a situaciones en las que los datos están almacenados en distintos departamentos o sistemas sin comunicación entre ellos, dificultando el acceso y el análisis integrado.
Ante esta situación en cuanto a localización, comunicación, integración y estructura de datos, algunos asistentes caen en la tentación de rendirse. “Entonces no puedo hacer People Analytics… con la ilusión que me hacía”. ¡Nada de eso! Tenemos diferentes soluciones. Comencemos, al menos, con los datos estructurados a los que tenemos acceso. En este sentido, mi primera recomendación es realizar un mapa de datos para levantar de forma, ahora sí, concienzuda y rigurosa, todas las fuentes de datos de RRHH que te puedan interesar.
| Un mapa de datos es un diagrama o documento que describe qué datos existen en la organización, dónde están almacenados, cómo están conectados y quién tiene acceso. Es clave para gobernanza de datos, integración y cumplimiento normativo (ej. GDPR).
Elementos fundamentales en un mapa de datos:
|
No os voy a engañar, no es una tarea divertida, pero es la base para poder empezar. Una vez que la tenemos, disponemos de dos opciones:
- Pedir a IT que nos monte un data mart o que añada nuestros datos al data warehouse que ya estén montando. Esta es la mejor opción, pero no la más rápida. Pedid el tique a IT, pero no os sentéis a esperar. Vayamos a la opción b.
- Comenzar a trastear usando herramientas de visualización de datos. Aquí os sonarán algunos nombres, sobre todo los de las herramientas de las que Microsoft y Google son propietarios. Con ellas podemos llamar a diferentes orígenes de datos e incluso conectar esos ficheros Excel que tanto nos avergüenzan y a la vez necesitamos, y así explotar la información desde un único lugar.
En fin, si algo queda claro después de hablar de datos en RR.HH. es que están dispersos, son heterogéneos y son complejos de integrar. ¡Pero rendirse no es una opción!
Empieza levantando un mapa de datos. Haz el trabajo sucio: localiza todas tus fuentes y entiende cómo podrías conectarlas. Si IT tarda siglos en darte acceso a un data mart, no te quedes esperando. Trastea con herramientas de visualización, juega con los datos que ya tienes y encuentra patrones. No hace falta ser un data scientist para empezar, solo curiosidad y ganas de entender lo que está pasando en tu organización en relación con la gestión de personas.
¿Te atreves a dar el primer paso?






