No sé a ti, pero me fastidia que los ordenadores y aplicaciones de Internet se pasen de inteligentes, y hagan cosas por mí que no les pido, subestimando mi capacidad de decidir como la persona adulta que soy. Eso es lo que hacen los algoritmos de personalización, un misterio inescrutable que condiciona la experiencia de usuario (mucho más de lo que puedas imaginarte) en la mayoría de las plataformas que utilizamos en Internet.
Facebook, Google, Pinterest y otras fuentes habituales de información usan algoritmos de filtrado (Algorithmic Filtering) para decidir qué vemos y qué no. Lo que entrega nuestra pantalla desde esas aplicaciones no es una colección trasparente de entradas ordenadas en orden cronológico. No ves “lo que hay”, sino una selección de contenidos que ellos han hecho por ti. Esos algoritmos arbitran qué es útil o relevante a partir de nuestro historial de navegación, de búsquedas y de clics, y otros criterios secretos que ni tu, ni yo, conocemos.
Lo más preocupante es que, como advierten los investigadores sociales, hay una enorme brecha entre la comprensión pública de los algoritmos y su prevalencia e importancia en nuestras vidas. No hay, por decirlo de algún modo, una “consciencia algorítmica” que fomente una mayor cultura de control sobre Google, Facebook y el resto de las plataformas que disfrutan hoy de una posición dominante.
Por ejemplo, según un estudio de 2014 la mayoría de los usuarios de Facebook ni siquiera sabía que esta plataforma utiliza algoritmos para filtrar las noticias que ven. El proyecto FeedVis ayudó a constatar esto con un recurso visual muy sencillo: mostrando a la izquierda todos los mensajes que publican nuestros amigos en Facebook, y a la derecha las actualizaciones de estado que nos llegan realmente a nuestro muro. Los usuarios se asombraron de lo diferentes que eran ambas columnas, y de cuántas cosas no les llegaban por simple decisión de Facebook. Muchos se molestaron al comprobar que incluso se les ocultaban entradas de sus familiares y seres queridos.
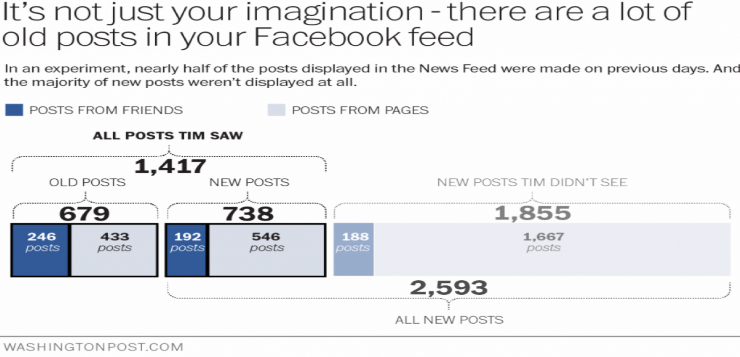
Para la mayoría de los participantes esa era la primera vez en que se enteraban que había un algoritmo mediando las entradas que publicaba Facebook. El 37,5% de los participantes era consciente de eso, pero el 62,5% no lo sabía. En el artículo que estoy reseñando también comparten otro experimento hecho por un reportero de The Washington Post que demostraba que cerca de la mitad de las entradas que dejaba ver Facebook eran contenidos reciclados, o sea, que se habían publicado en días anteriores, y que casi el 60% de las entradas de nuestros amigos no se reflejan en nuestro muro [Ver imagen].
Este es un tema que me interesa y me alarma en partes iguales. Por eso puse tanto interés en un soberbio artículo que descubrí el viernes de Caitlin Dewey en The Washington Post, publicado en marzo de este año: “What you don’t know about Internet algorithms is hurting you. (And you probably don’t know very much!)”. Le he dedicado unas cuantas horas del fin de semana a navegar por los enlaces y completar información para poder escribir esta reseña.
Por ordenar un poco el asunto, pienso que estos algoritmos pueden perjudicar nuestra experiencia del usuario de dos maneras:
1) Personalización “recursiva”: Así voy a llamar al efecto de reducir las posibilidades de encontrar información que se aparte de nuestras preferencias habituales y del patrón de búsqueda seguido antes. Una “relevancia” predeterminada por algún algoritmo deja fuera a contenidos que podrían interesarnos, y sorprendernos.
2) Personalización “corrupta”: El algoritmo que decide la “relevancia” incorpora variables que no son beneficiosas para el usuario sino para los intereses comerciales o de otro tipo del canal. Como resultado de ello, optimiza la “personalización” en función de las expectativas empresariales de Facebook o de Google, y no del usuario.
Voy a explicar ahora, en detalle, cada uno de estos dos efectos por separado.
Personalización “recursiva”:
La personalización que hacen los buscadores tiene, obviamente, sus ventajas. Que filtren la información con resultados familiares es cómodo y nos produce una agradable sensación de control. Se ahorra uno el trabajo de tener que buscar, y ya sabemos que los atajos en Internet son adictivos. Pero predecir lo que nos interesa basándose en nuestras preferencias anteriores hace que la lógica del “dame-más-de-lo-mismo” reduzca las probabilidades de encontrar información nueva. A más repetimos un patrón de búsqueda, más estrecho se vuelve el universo de contenidos que el buscador entrega.
Le he llamado personalización “recursiva” porque es como si una cadena de búsquedas se invocara a sí misma, generando un largo bucle que nos encierra cada vez más en una trampa de contenidos homogéneos. Ya comenté en un post anterior el riesgo que corremos de crearnos burbujas sociales y cámaras de eco si olvidamos introducir diversidad en nuestros patrones de acceso a la información. Eli Pariser bautizó con el nombre de la “Burbuja del Filtro” (“The Filter Bubble”) ese efecto redundante y empobrecedor que pueden generar los algoritmos de personalización. Aquí tienes un vídeo de una charla-TED de Pariser hablando del tema.
Imaginando un resultado ideal y que todos los contenidos que nos entregue el algoritmo nos gusten, ¿qué tiene de malo ver, oír y leer exactamente lo que uno quiere? El riesgo está en que dejen fuera información que nos convendría saber: ¿y si nos estamos perdiendo cosas interesantes porque no encajan en nuestros patrones anteriores de búsqueda? El efecto de este mecanismo recursivo de curación de contenidos puede ser una pérdida significativa de la diversidad.
La autora del artículo de The Washington Post pone un ejemplo personal usando Pinterest. A ella le encanta cocinar, así que acostumbra a buscar recetas originales en esa red social, pero empezó a notar que se repetía el mismo puñado de recomendaciones: coles de Bruselas, sopa de lentejas, requesón con miel y otras que son, en efecto, sus favoritas; y que ahora le cuesta más descubrir recetas que le sorprendan como antes. La explicación la encontró en un post de Pinterest que anunciaba un cambio en su algoritmo de selección de contenidos “para mejorar la personalización”. Como a ella le encantan las coles de Bruselas, le ponían más recetas que contenían esas coles 🙂
O sea, si mi predisposición de búsqueda es racista, xenófoba o machista, entonces el filtro incorpora esos sesgos y me elige contenidos que tienden a responder a ese patrón, lo que puede perpetuar mis perjuicios.
Personalización “corrupta”:
Este término tan apropiado no es mío sino del investigador social Christian Sandvig, y se refiere a la personalización que sirve a intereses ajenos, y no a los nuestros.
Hablemos claro. La gestión algorítmica de la atención que hacen Google o Facebook no es “por nuestro propio bien”, sino dictada sobre todo por intereses corporativos. El modelo de negocio de estos gigantes no consiste en ayudarnos, sino en maximizar los ingresos de los anunciantes a partir de la ingente cantidad de datos que manejan de los usuarios. Es así como los límites de la publicidad en estas plataformas es cada vez más borrosa, mezclándose lo comercial con lo que no lo es de un modo alarmante. Y ese es un problema generalizado porque basta con que un canal sea lucrativo, llámese Google, Facebook o TeQuiero SA, para que tenga los mismos incentivos de monetizar nuestra atención.
Igual que hay intereses empresariales, también los hay políticos. De hecho se habla cada vez más de los algoritmos como una forma de “control social”, o como una metáfora de lo sutil que puede ser la tecnología como herramienta de manipulación. Los sociólogos incluso se preguntan: ¿Se podría llegar a la situación de ocultar hechos relevantes por la “censura logarítmica” de Facebook?
La socióloga Zeynep Tufekci abunda en esa cuestión acusando a Facebook de oscurecer algorítmicamente las noticias de las protestas raciales en la ciudad norteamericana de Ferguson. La activista notó que la cobertura de los disturbios en Facebook tuvo un sospechoso retardo respecto de la proyección que tuvo en Twitter. Las actualizaciones de estado de amigos y conocidos sobre lo que ocurría en Ferguson no se publicaban inmediatamente, y se dio preferencia a un material más ligero, con más atractivo cultural pop. En un artículo posterior, Tufekci reconoce sentirse descolocada con este misterio algorítmico que convierte de facto a estos canales en “máquinas de juzgar” (“judging machines”) porque son ellos los que determinan qué es más relevante, útil y apropiado para nosotros.
Auditoría de algoritmos
A pesar de que (y no exagero) los algoritmos de personalización dan forma a la manera en que pensamos y lo que sabemos, siguen siendo cajas negras propietarias. Ni Facebook, ni Amazon, ni Google, ni Pinterest publica los entresijos de su código, ni nadie sabe cómo funcionan. ¿Podrían ser transparentes? Sinceramente creo que no, porque conocerlos los convertiría en carne de cañón de spammers y hackers. Sabiendo exactamente cómo filtran permitiría manipular el posicionamiento de los contenidos. Pero afortunadamente hay otras soluciones, que comentaré.
Como tenemos pocas razones para confiar en que las empresas van a tener la voluntad de actuar en nuestro interés sin una supervisión regulatoria, algunos científicos como Christian Sandvig empiezan a hablar de un nuevo campo de investigación académica, la “auditoría de algoritmos” (“Social Science Audits of Algorithms”), que se dedica a estudiar los algoritmos de Internet con el fin de averiguar qué los motiva y qué puede estar mal en ellos desde el punto de vista ético, cultural o político. Esto, a su vez, debería (añado yo) tener un reflejo en el marco normativo, en las leyes que protegen a los ciudadanos.
Sandvig y otros investigadores defienden las auditorías como un mecanismo eficaz para evitar abusos. El método consistiría en enviar contenidos ficticios a esas plataformas y ver cómo éstas los procesan, para comprobar si no incurren en sesgos inaceptables. Esta investigación la harían expertos imparciales e independientes (obviamente, no financiados por Google y Cía.). Según estos científicos, a pesar de la complejidad de estos algoritmos sería posible determinar si incurren en prácticas que perjudiquen a los usuarios, porque el mecanismo de ensayo-error puede ayudar a desentrañar las reglas que fijan las interacciones entre el algoritmo y los datos. Lo que necesitamos es “saber cuándo un algoritmo de personalización está trabajando para nosotros, o para otros intereses”.
Pero yo no esperaría a que esas auditorías desvelen las trampas de códigos que ocultan esos algoritmos. La mejor solución es, y seguirá siendo, cambiar nuestros hábitos de consumo de información siendo más críticos con las fuentes e introduciendo diversidad de forma deliberada. Escribiré pronto un nuevo post con consejos prácticos que pueden servirte para escapar de los sesgos de la personalización.